Over $16,000 Worth of Prizes to be Won During Trail Karma Month

More so than before, trail associations are spread thin as trail maintenance increases and access to resources decreases. Due to COVID-19, funding is being cut, while more and more people are outside using the trails. There is a large gap between current funding and what is required to build and maintain the trails that bring us so much joy. Which got us thinking...
For the month of July, we’re giving you more reason to give back to the trails you love to enjoy with Trail Karma Month. Trail Karma Month is a campaign to raise awareness and increase funding for trail associations around the world.
We are encouraging everyone around the world to support their favourite trails by donating via Trail Karma in July. Trail Karma provides a direct way for you to put 100% of your donation into trail associations and builders developing trail systems.
Donate to a trail association(s) of your choice between July 1st - 31st. 2020 for a chance to win one of our incredible prizes listed below.
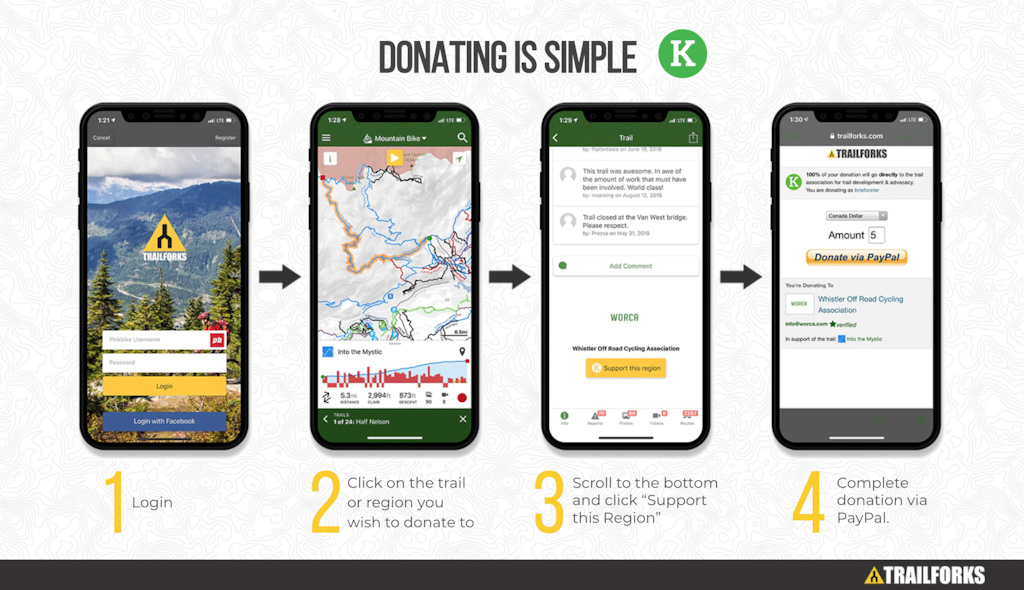
For a chance to win
Prizes

Prize description:
- 6 night/7 day trip for 2 (winner and a friend)
- 2 nights’ accommodation in each location; North Vancouver (aka North Shore), Squamish, and Whistler
- ½ day local guide in each location to get you orientated with the trails.
- Extra goodies from each location including Capilano Suspension Bridge, Sea to Sky Gondola, local breweries and more
- 7-day bike rental for 2
- Ground transportation between Vancouver International Airport (YVR) and Whistler (voucher for 7 day rental car will be arranged if winner is aged 25 or older)
Full details about the getaway can be found here.


4x Bundle Prize Packs Including (one of each):
2x $500 Jenson USA Gift Certificates

How It Works
• For every donation between July 1st, 2020 - 12:01am PT and July 31st, you will earn Trail Karma to win one of these awesome prizes provided by our sponsors.
• Minimum donation of $5 is required for entry
• Each Trail Karma point gives you 1 entry. If you donate $5, you get 3 points = 3 entries.

• The winners will be notified by e-mail and asked a mountain bike related knowledge question.
Where does my money go?
• 100% of your money goes directly to the trail association of your choice when you donate and does not transfer hands.
For more information, head over to Trailforks.
Contest Rules


Author Info:

Must Read This Week
Sign Up for the Pinkbike Newsletter - All the Biggest, Most Interesting Stories in your Inbox
PB Newsletter Signup
When Whistler is charging $80 for one day of riding it's also easy to justify a couple bucks here and there to the local guys.
If you donate via Trailforks Trail Karma, I personally work with the associations to make sure they get their donation.
Example:
Donate $5 to 3 different trails, receive 9 points
Donate $15 to 1 trail get 10 points
Help
$5 to $14.99 gets you 3 Karma Points
$15 to $24.99 gets you 10 Karma Points etc etc.
What association or region are you trying to donate to?
What year is this..
PayPal is one of, if not the safest way to send money.
Would you prefer cash in an envelope?
PayPal is the easiest way for use to administer the Trail Karma Program. Once we link the associations PayPal information in Trailforks it's is basically hands off for us. Plus 99% of associations use PayPal to receive donations.